Stable Diffusion101(壹)

Stable Diffusion101(壹)
JialaiStable Diffusion101(壹)
Stable Diffusion原理
基本原理
Stable Diffusion的核心原理是扩散模型(Diffusion Model)。扩散模型的工作过程可以类比为将一张清晰的图像逐步添加噪声,使其变得模糊,再学习如何从模糊的图像中逐步去除噪声,恢复出原始图像。
正向扩散过程:在正向扩散过程中,模型会逐步向原始图像添加高斯噪声,经过T步后,图像将变成完全的噪声。
反向扩散过程:在反向扩散过程中,模型学习从噪声中逐步去除噪声,恢复出原始图像。
训练过程:通过大量图像数据,模型学习如何在反向扩散过程中预测每一步需要去除的噪声,从而实现从噪声生成图像的能力。
整体架构

这张图展示了 Stable Diffusion 模型的主要组成部分以及它们之间的数据流动关系。模型主要分为两大块:
- 文本编码器(Text Encoder):负责将输入的文本提示(prompt)转换为机器可以理解的向量表示。
- 图像生成器(Image Generator):基于文本向量和其他条件(如时间步等),逐步从噪声中生成图像。
文本编码器(Text Encoder)部分
- CLIP-G/14 & CLIP-L/14:这是两个 CLIP(Contrastive Language-Image Pre-training)模型,用于将文本提示编码成 embedding 向量。CLIP 模型通过对比学习,将图像和文本映射到同一空间,使得语义相似的图像和文本具有相近的向量表示。
- CLIP 是 OpenAI 开发的一种多模态模型,旨在学习图像和文本之间的关联。它通过对比学习的方式,将图像和文本映射到同一个语义空间,使得语义相似的图像和文本具有相近的向量表示。CLIP 的核心思想是对比学习(Contrastive Learning)。简单来说,对比学习就是让模型学会区分哪些样本对是相似的,哪些样本对是不相似的。在 CLIP 中,相似样本对是一张图像和它的文本描述,不相似样本对则是一张图像和其他不相关的文本描述。
- T5 XXL:这是一个大型的文本生成模型,可能用于进一步处理或增强文本提示的表示。
- Pooled Output:这是文本编码器的最终输出,是一个包含文本提示语义信息的向量。
其中:
“77+77 tokens” 和 “4096 channels” 代表:
77+77 tokens
- tokens:在自然语言处理中,token 是指文本的基本单位,可以是一个词、一个子词或一个字符。
- 77+77 tokens:这是指 Stable Diffusion 模型在处理文本提示(prompt)时,最多可以接受 77 个 token,额外的tokens(这里的77个)会被cut掉。
- 限制原因:这个限制主要来自于模型训练时使用的文本编码器(CLIP),其最大输入长度为 77 个 token。
- 超出限制的影响:如果 prompt 超过了这个限制,多余的部分将被忽略,可能导致生成的图像不符合预期。
- 注:Negative prompt 和 positive prompt 会一起包含在77 个 token 中。
4096 channels
- 在计算机视觉和深度学习中,”channels” 通常指的是图像或特征图(feature map)的通道数。每个通道可以看作是一个二维矩阵,其中每个元素代表图像在该通道上的某个位置的数值。
- 对于彩色图像,通常有 3 个通道,分别代表红(R)、绿(G)和蓝(B)三种颜色。每个像素点的颜色由这三个通道的数值组合而成。
- 对于灰度图像,只有一个通道,每个像素点的数值代表其亮度。
- 对于深度学习模型中的特征图,通道数可以是任意的,每个通道代表模型在不同层次上提取到的特征。可以将通道数理解为图像或特征图的深度或厚度。比如:
- 彩色图像的 3 个通道 分别表示图像在红、绿、蓝三个颜色维度上的信息。
- 深度学习模型中的特征图的多个通道 分别表示模型在不同抽象层次上提取到的特征,例如边缘、纹理、形状等。
- 在 Stable Diffusion 中,4096 channels 指的是模型在生成图像的过程中,中间特征图的通道数。这意味着模型在每个位置上提取了 4096 个不同的特征,用于表示图像的各种信息。
- Channel 中的数据类型通常是浮点数(float),表示图像或特征在该通道上的强度或响应。对于图像,浮点数通常在 0 到 1 之间,表示像素点的颜色或亮度。对于深度学习模型中的特征图,浮点数的取值范围可以是任意的,取决于模型的具体实现。
- 权衡:更多的通道数也会增加模型的计算复杂度和内存占用。
池化(Pooling):
Pooling是深度学习中常用的一种降维技术。它通过对输入数据进行某种聚合操作(例如取最大值、平均值等),将输入数据的大小减小,同时保留重要的特征信息。将文本编码器生成的特征图(feature map)进行降维,得到一个固定长度的向量表示(pooled output)。
具体来说,pooling 操作可以:
- 降低维度:文本编码器生成的特征图通常具有较高的维度,不利于后续计算。Pooling 操作可以将特征图的维度降低,提高计算效率。
- 提取全局特征:Pooling 操作可以将特征图中的局部特征聚合为全局特征,从而更好地捕捉文本提示的整体语义。
- 增强鲁棒性:Pooling 操作可以减少特征图对微小变化的敏感性,提高模型的鲁棒性。
在文本编码器中,常用的 pooling 操作包括:
- Max Pooling:取特征图中每个区域的最大值作为输出。
- Average Pooling:取特征图中每个区域的平均值作为输出。
- Attention Pooling:通过注意力机制(attention mechanism)对特征图进行加权平均,得到输出。
以Max Pooling为例:
假设我们有一个 4x4 的特征图(feature map),如下所示:
1 | 1 2 3 4 |
我们对这个特征图应用一个 2x2 的 Max Pooling,步长(stride)为 2。这意味着我们将特征图分成 2x2 的不重叠区域,然后从每个区域中取最大值作为输出。
具体操作如下:
- 划分区域:将特征图划分成 4 个 2x2 的区域:
区域 1:
- 1 2
- 5 6
区域 2:
- 3 4
- 7 8
区域 3:
- 9 10
- 13 14
区域 4:
- 11 12
- 15 16
- 取最大值:从每个区域中取最大值:
区域 1 的最大值是 6
区域 2 的最大值是 8
区域 3 的最大值是 14
区域 4 的最大值是 16
- 输出:将这些最大值组合成一个 2x2 的输出特征图:
1 | 6 8 |
可以看到 Max Pooling 操作将原始特征图的大小减小了一半,同时保留了每个区域中最显著的特征(最大值)。这种降维和特征提取的能力使得 Pooling 操作在深度学习中广泛应用。
其他类型的 Pooling
除了 Max Pooling,还有其他类型的 Pooling 操作,例如:
- Average Pooling:取每个区域的平均值作为输出。
- Global Pooling:将整个特征图聚合为一个值,例如全局最大池化或全局平均池化。
Attention机制和Attention Pooling:
Attention 机制(注意力机制)是一种模拟人类注意力分配的机制,它可以让模型在处理信息时,重点关注那些与当前任务更相关的信息,而忽略那些不重要的信息。
在深度学习中,注意力机制通常通过计算一个权重向量来实现,这个权重向量表示每个输入元素的重要程度。然后,模型会根据这个权重向量对输入元素进行加权平均,得到最终的输出。
假设,我们有一个文本序列 “我喜欢吃苹果和香蕉”,经过文本编码器后,得到了每个词的向量表示:
- 我:[0.1, 0.2, 0.3]
- 喜欢:[0.4, 0.5, 0.6]
- 吃:[0.7, 0.8, 0.9]
- 苹果:[0.2, 0.3, 0.4]
- 和:[0.5, 0.6, 0.7]
- 香蕉:[0.8, 0.9, 0.1]
现在,我们想要通过 Attention Pooling 得到整个句子的向量表示。首先,我们需要计算每个词的权重。假设我们通过某种方式得到了以下权重向量:
- 我:0.1
- 喜欢:0.2
- 吃:0.3
- 苹果:0.2
- 和:0.1
- 香蕉:0.1
然后,我们对每个词的向量表示乘以其对应的权重,再将结果相加,得到最终的句子向量表示:
1 | 句子向量 = 0.1 * [0.1, 0.2, 0.3] |
在 Stable Diffusion 的文本编码器中,Attention Pooling 用于将文本编码器生成的特征图(每个 token 的向量表示)聚合为一个固定长度的向量,表示整个文本提示的语义。
图像生成器(Image Generator)
- Noised Latent:这是输入到图像生成器的初始噪声图像,其维度与最终生成的图像的潜在表示(latent representation)相同。
- Patching & Unpatching:将噪声图像分割成小块(patch),并在生成过程的最后将这些小块重新组合成完整的图像。
- Timestep:表示当前生成过程所处的时间步,从大到小,意味着图像从噪声逐渐变得清晰。
- Sinusoidal Encoding:将时间步信息编码成向量,提供给模型。
- MM-DiT Blocks:这是图像生成器的核心部分,由多个 MM-DiT(Multi-Modal Diffusion Transformer)块组成。每个块内部包含:
- Attention:自注意力机制,用于建模图像不同区域之间的关系。
- MLP(Multi-Layer Perceptron):多层感知机,用于特征提取和转换。
- Modulation:将文本向量、时间步等条件信息融入到模型中,指导图像生成。
- LayerNorm & Linear:层归一化和线性变换,用于稳定训练和调整特征维度。
PS: 关于Transformer:
Transformer 模型主要由编码器(Encoder)和解码器(Decoder)两部分组成。

编码器:负责处理输入序列,生成一组特征表示。它由多个相同的层堆叠而成,每个层包含两个子层:
- 多头自注意力层(Multi-Head Self-Attention):允许模型在处理序列中的每个元素时,关注序列中的所有其他元素,从而捕获它们之间的依赖关系。
- 前馈神经网络层(Feed-Forward Network):对每个位置的特征进行独立的非线性变换。
解码器:负责根据编码器生成的特征表示和先前生成的输出,逐个生成目标序列。它也由多个相同的层堆叠而成,每个层除了包含编码器中的两个子层外,还增加了一个子层:
- 编码器-解码器注意力层(Encoder-Decoder Attention):允许解码器关注输入序列中的相关部分。
Transformer 的特点
- 并行计算:Transformer 抛弃了传统的循环神经网络(RNN)结构,采用自注意力机制,使得模型可以在处理序列时进行并行计算,大大提高了训练和推理速度。
- 全局信息捕捉:自注意力机制允许模型在处理序列中的每个元素时,关注序列中的所有其他元素,从而能够捕捉全局信息,尤其擅长处理长距离依赖关系。
- 可解释性:注意力机制的可视化可以帮助我们理解模型在处理序列时关注哪些部分,提高了模型的可解释性。
Transformers和RNN:
RNN:

RNN(循环神经网络)是一种专门用于处理序列数据的神经网络。它的核心思想是在处理序列中的每个元素时,都会考虑前面元素的信息。这种信息传递是通过一个隐藏状态(hidden state)来实现的。
- 输入层:接收序列中的每个元素作为输入。
- 隐藏层:对输入进行处理,并生成一个隐藏状态。这个隐藏状态会传递给下一个时间步,用于处理下一个元素。
- 输出层:根据隐藏状态生成输出。
Transformer 中的自注意力机制允许模型同时处理序列中的所有元素,而不需要等待前一个元素的计算结果。这种并行计算能力使得 Transformer 在处理长序列时具有更高的效率。
ComfyUI
基础右键Menu:

Add Node:这个选项用于向工作区添加新的节点。点击后,会弹出一个节点选择窗口,你可以从中选择需要的节点类型,如加载模型、输入提示词、设置采样器等。
Add Group:这个选项用于创建一个空的节点组。节点组可以将多个节点打包在一起,方便管理和复用。
Group(组)的主要作用是组织和管理节点,将多个相关的节点打包在一起,使其更易于管理、复用和共享。你可以将Group看作是一个容器,它可以包含任意数量和类型的节点,并且可以嵌套其他Group。
注意:Group只在当前的workflow中生效
例如:
假设你正在构建一个文生图流程,其中涉及到加载模型、输入提示词、设置采样器、生成图像等多个节点。你可以将这些节点打包成一个Group,命名为”文生图流程”。这样,你就可以将这个Group作为一个整体来移动、复制、粘贴,甚至保存为模板,方便在其他工作流程中复用。
Add Group For Selected Nodes:选择一些节点,并将这些节点打包成一个新的节点组。
Convert to Group Node:这个选项将当前选中的节点转换为一个节点组节点。节点组节点可以像普通节点一样连接到其他节点,但它内部包含了一个完整的工作流程。
Group与Workflow的区别
- Workflow(工作流程):ComfyUI中的Workflow代表一个完整的图像生成或处理过程,它包含了从加载模型到保存图像的所有必要节点。一个Workflow可以包含多个Group。
- Group(组):Group是Workflow中的一个组成部分,用于组织和管理节点。Group本身并不代表一个完整的工作流程,它需要与其他节点或Group连接才能发挥作用。
Group与Template的区别
- Group(组):Group是一个动态的容器,你可以随时向其中添加、删除或修改节点。Group的主要作用是在当前Workflow中组织和管理节点。
- Template(模板):Template是一个静态的节点集合,它保存了特定节点的配置和连接方式。Template的主要作用是在不同的Workflow中复用节点配置,提高工作效率。
Save Selected as Template:如果你选择了一些节点,这个选项会将这些节点保存为一个模板。模板可以方便地复用,加快工作流程的搭建。
Node Templates:这个选项打开节点模板库,你可以在这里浏览、加载和管理已保存的节点模板。
Add Node右键Menu:
utils: 其中有注释工具,基本几何绘制工具,整理排线工具和debug的terminal等。
sampling:提供各种采样器(Sampler)节点,用于从模型中生成图像。设置采样步数、CFG Scale 等参数,控制图像生成过程。
loaders:提供各种加载器节点,用于加载模型、图像、文本等数据。
conditioning:提供各种条件节点,用于控制图像生成过程。
latent:提供各种潜在空间(latent space)操作节点,用于在模型的潜在空间中处理图像。比如图像编码和解码:使用 VAE Encode 和 VAE Decode 节点将图像在像素空间和潜在空间之间转换等。
image:与图像相关的操作,加载预览,也提供各种图像处理节点,用于在像素空间中处理图像,修改大小,翻转等等
mask:提供各种掩码操作节点,用于创建、编辑和应用掩码。
_for_testing:包含一些用于测试和调试的节点,通常在开发或实验新功能时使用。
advanced:包含一些高级节点,用于实现更复杂的功能。
model_patches:包含一些用于修改模型行为的节点。
audio:包含一些用于处理音频数据的节点。
ImpactPack:包含一些由 ImpactPack 社区开发的节点。
postprocessing:包含一些用于图像后处理的节点。
ControlNet Preprocessors:包含一些用于 ControlNet 的预处理节点。
Derfuu_Nodes:包含一些由 Derfuu 开发的节点。
Efficiency Nodes:包含一些用于提高效率的节点。
api:包含一些用于与外部 API 交互的节点。
以上为简要概括,详情请见另一篇Post,关于右键菜单的详解。
基本文生图Workflow

Workflow 逻辑
这个 workflow 的核心逻辑是:
- 加载模型:使用
Checkpoint Loader加载 Stable Diffusion 的基础模型。 - 加载 LoRA:使用
LoRA Loaders加载一个或多个 LoRA 模型,用于对基础模型进行微调,实现风格定制或其他效果。 - 文本编码:使用
CLIP Text Encode节点将正向提示词(positive prompt)和负向提示词(negative prompt)编码成向量表示。 - 图像编码:使用
VAE Encoder将随机噪声或初始图像编码到潜在空间(latent space)。 - 采样:使用
Sampler在潜在空间中进行迭代采样,逐步从噪声中生成图像。采样过程中会受到文本编码和 LoRA 的影响。 - 图像解码:使用
VAE Decoder将潜在空间中的图像解码回像素空间。 - 输出图像:使用
Image Output节点显示或保存生成的图像。
每一项的操作和作用
Checkpoint Loader:加载 Stable Diffusion 的基础模型,提供了生成图像的核心能力。PS: 如何训练大模型:
详细步骤
- 数据准备
数据集:Stable Diffusion 的训练通常使用大规模的图像-文本对数据集,如 LAION-5B 或 LAION-Aesthetics。这些数据集包含数百万甚至数十亿的图像和文本描述。
数据预处理:对图像进行预处理,如调整大小、裁剪、归一化等。对文本进行分词、编码等处理。
- 模型架构
变分自编码器(VAE):用于将图像编码为低维度的潜在表示(latent representation),并在生成过程中将潜在表示解码回图像。
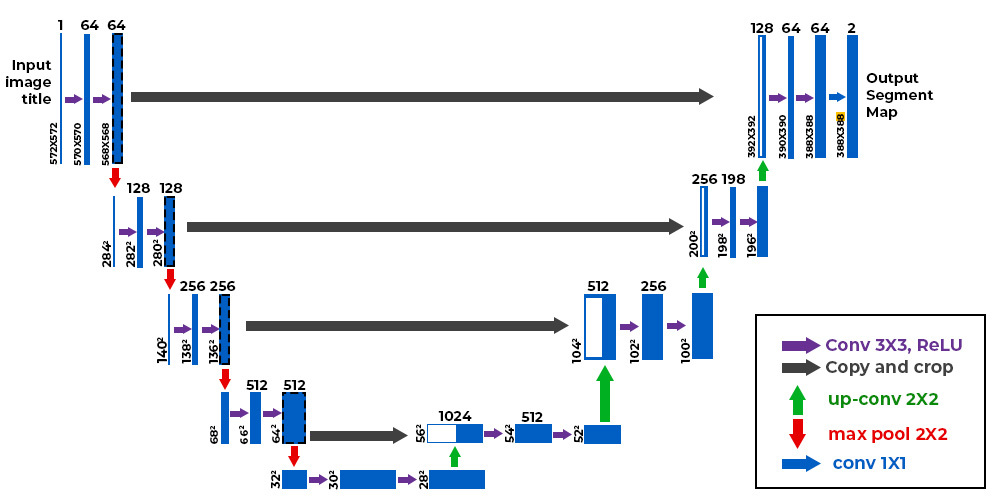
U-Net:用于在潜在空间中进行图像生成。U-Net 是一种具有 U 形结构的卷积神经网络,它通过多次下采样和上采样操作,逐步提取和融合图像的特征。
U-Net 是一种特殊类型的卷积神经网络(CNN),因其结构形似字母 U 而得名。它最初被设计用于生物医学图像分割任务,但由于其在处理图像细节和全局上下文信息方面的优势,现在被广泛应用于各种图像生成和处理任务中,包括 Stable Diffusion。
U-Net 在 Stable Diffusion 中的作用
在 Stable Diffusion 中,U-Net 负责在潜在空间中对图像进行去噪和生成。具体来说,它接受一个带有噪声的潜在图像作为输入,并尝试预测出需要从图像中去除的噪声。通过迭代地应用 U-Net,我们可以从一个完全是噪声的图像开始,逐步去除噪声,最终生成一张清晰的图像。
U-Net 的实现方法
U-Net 的结构主要由以下几个部分组成:

下采样路径(contracting path):
图的左侧部分,从输入图像开始,到中间最窄的部分。
- 特征提取:通过卷积层,从输入图像中提取不同层次的特征,如边缘、纹理、形状等。
- 降低分辨率:通过池化层(通常是最大池化),降低特征图的空间分辨率,减少计算量,同时扩大感受野,让模型能够捕捉到更大范围的上下文信息。
瓶颈层(bottleneck):
图的中间最窄的部分。
- 连接下采样路径和上采样路径。
- 进一步提取图像的全局特征。
上采样路径(expansive path):
图的右侧部分,从瓶颈层开始,到输出图像结束。
- 恢复分辨率:通过转置卷积(或上采样+卷积),逐步提高特征图的空间分辨率,恢复图像的细节。
- 精细化特征:结合来自下采样路径的跳跃连接,在上采样过程中逐步完善图像的细节和语义信息。
跳跃连接(skip connections):
- 将下采样路径中的特征图直接连接到上采样路径中对应层的输入。
- 保留细节:将下采样路径中的高分辨率特征图直接传递到上采样路径中,帮助模型在恢复分辨率的过程中保留图像的细节信息。弥补下采样过程中的信息丢失,提高模型的生成质量。
实例:图像去噪
让我们通过一个简单的图像去噪任务来理解 U-Net 的工作原理。
假设我们有一张带有噪声的图像,我们希望使用 U-Net 来去除噪声。
- 输入:将带有噪声的图像输入到 U-Net 中。
- 下采样:U-Net 的下采样路径会逐步提取图像的特征,并降低特征图的空间分辨率。
- 瓶颈:在瓶颈层,U-Net 进一步提取图像的全局特征。
- 上采样:U-Net 的上采样路径会逐步提高特征图的空间分辨率,并利用跳跃连接从下采样路径中获取细节信息。
- 输出:U-Net 的输出是一张去噪后的图像,其中噪声被尽可能地去除。
文本编码器:用于将文本提示编码为向量表示,为 U-Net 提供条件信息。
- 损失函数
Stable Diffusion 的损失函数主要由两部分组成:
重构损失:衡量模型生成的图像与真实图像之间的差异,通常使用均方误差(MSE)或其他相似度度量。
条件损失:衡量模型对文本提示的理解程度,通常使用对比学习损失或其他文本-图像匹配损失。
- 优化器
Stable Diffusion 通常使用 Adam 优化器或其变种进行训练。Adam 优化器是一种自适应学习率优化算法,它可以根据梯度的大小自动调整学习率,从而加速模型收敛。
- 训练
- 迭代训练:在大量图像-文本对数据集上进行迭代训练,每次迭代包括前向传播、损失计算、反向传播和参数更新等步骤。
- 扩散过程:Stable Diffusion 的训练基于扩散模型,它通过逐步向图像中添加噪声,然后学习如何从噪声中恢复出原始图像。
- 训练技巧:为了提高模型的性能和稳定性,可能会采用一些训练技巧,如梯度裁剪、学习率调度、权重衰减等。
CitivAI上的Checkpoint训练:
主要有以下几种:
1. DreamBooth
- 原理:DreamBooth 是一种微调技术,旨在让模型学习特定概念(例如一个物体、一个人、一种风格等)的表示。它通过在少量目标图像上进行训练,同时保持模型在其他概念上的泛化能力。
- 优点:
- 只需要少量目标图像(通常 3-5 张)。
- 训练速度相对较快。
- 可以生成高质量、忠实于目标概念的图像。
- 缺点:
- 需要仔细选择目标图像和提示词。
- 可能存在过拟合问题,导致模型在生成其他概念时表现不佳。
2. Textual Inversion
- 原理:Textual Inversion 是一种在模型的词嵌入空间中学习新概念表示的方法。它通过训练一个特殊的词嵌入向量,使得模型能够理解和生成与该概念相关的图像。
- 优点:
- 只需要少量目标图像。
- 训练速度非常快。
- 生成的图像具有高度可控性。
- 缺点:
- 学习到的概念表示可能不够稳定。
- 生成的图像质量可能不如 DreamBooth。
3. Hypernetwork
- 原理:Hypernetwork 是一种通过训练一个小型的神经网络来修改 Stable Diffusion 模型权重的方法。这个小型神经网络将文本提示或其他条件信息作为输入,输出对 Stable Diffusion 权重的调整,从而实现对图像生成过程的控制。
- 优点:
- 可以实现对图像的精细控制。
- 训练速度相对较快。
- 模型文件大小较小。
- 缺点:
- 需要一定的调参经验。
- 生成的图像质量可能不如 DreamBooth。
4. Fine-tuning
- 原理:Fine-tuning(微调)是指在预训练的 Stable Diffusion 模型上,使用新的数据集进行进一步训练,以适应特定任务或风格。
- 优点:
- 可以充分利用预训练模型的知识。
- 训练速度相对较快。
- 可以生成高质量的图像。
- 缺点:
- 需要一定数量的训练数据。
- 可能存在过拟合问题。
LoRA Loaders:加载 LoRA 模型,对基础模型进行微调,实现风格定制或其他效果。PS:LoRA是什么?如何制作LoRA:
LoRA(Low-Rank Adaptation) 是一种在神经网络中进行高效微调的技术。它通过在模型的特定层(通常是 Transformer 块中的注意力层)上添加低秩矩阵,来实现对模型的微调。这些低秩矩阵的参数量远小于原始模型的参数量,因此 LoRA 模型的大小通常都很小。
PS: 低秩矩阵:
矩阵的秩是指其线性无关的行向量或列向量的最大数目,可以理解为矩阵中的每个行、列向量都无法用其他行或列向量表示。通俗地说,秩代表了矩阵中真正包含的信息量或有效维度。秩越高的矩阵,包含的信息越丰富,表达能力越强。秩为满秩的矩阵,其行向量和列向量都是线性无关的。
如果一个矩阵的秩远小于其行数或列数,那么它就是一个低秩矩阵。 低秩矩阵的信息冗余度较高,可以用少量的基向量来近似表示,这也就代表了低秩矩阵的存储和计算成本较低,因为需要存储的(有效)数据量非常小。
低秩矩阵的核心思想是,原始矩阵中虽然有很多行或列,但它们之间可能存在很强的相关性。这些相关性意味着原始矩阵的信息冗余度较高,可以用少量的基向量来近似表示。
LoRA 就是利用了这个特点。它在原始模型的权重矩阵上添加两个低秩矩阵,通过两个低维向量的外积来构造一个完整的矩阵,从而用少量的参数来近似表示原始矩阵的变化。这两个低秩矩阵的参数量远小于原始权重矩阵,但却能捕捉到原始权重矩阵中的主要变化方向。LoRA 改变的是原始模型在特定任务或风格上的表现。通过调整低秩矩阵的参数,LoRA 可以引导模型生成特定风格的图像、调整模型对某些概念的理解、或者实现其他特定的效果。
题外话里的题外话:
举个例子:
假设我们有一个 3x3 的原始矩阵 A:
1
2
3
4
5A = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]现在,我们想要通过一个低秩矩阵来对 A 进行微调。为了简单起见,我们假设低秩矩阵的秩为 1。这意味着我们可以将低秩矩阵表示为两个向量的外积:
1
B = u * v^T
其中:
- u 是一个 3x1 的列向量。
- v 是一个 3x1 的列向量。
- v^T 是 v 的转置,是一个 1x3 的行向量。
让我们假设:
1
2u = [0.1, 0.2, 0.3]
v = [0.4, 0.5, 0.6]那么,低秩矩阵 B 为:
1
2
3
4
5B = [
[0.04, 0.05, 0.06],
[0.08, 0.10, 0.12],
[0.12, 0.15, 0.18]
]这里在做的是用一组基向量u和v近似表示A:
奇异值分解(SVD) 来找到 A 的一组基向量。SVD 将 A 分解为三个矩阵的乘积:
1
A = U * Σ * V^T
再举个例子中的例子:
假设我们有一个 3x3 的矩阵 A:
1
2
3
4
5A = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]我们可以通过奇异值分解(SVD)来找到 A 的一组基向量。SVD 将 A 分解为三个矩阵的乘积:
1
A = U * Σ * V^T
其中:
- U 是一个 3x3 的正交矩阵,它的列向量是 A 的左奇异向量。
- Σ 是一个 3x3 的对角矩阵,其对角线上的元素是 A 的奇异值,按照从大到小的顺序排列。
- V 是一个 3x3 的正交矩阵,它的列向量是 A 的右奇异向量。
假设 A 的奇异值分解结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17U = [
[-0.21483724, 0.88723069, 0.40824829],
[-0.52058739, 0.24964395, -0.81649658],
[-0.82633754, -0.38794274, 0.40824829]
]
Σ = [
[16.84810336, 0. , 0. ],
[ 0. , 1.06836987, 0. ],
[ 0. , 0. , 0.00000000]
]
V^T = [
[-0.47967118, -0.77669099, -0.40824829],
[-0.57236739, -0.07568647, 0.81649658],
[-0.6650636 , 0.61552563, -0.40824829]
]我们可以看到,Σ 中的第三个奇异值为 0,这意味着 A 的秩为 2。因此,我们可以只保留前两个奇异值和对应的左右奇异向量,得到一个秩为 2 的矩阵 B 来近似表示 A:
1
B = U[:, :2] * Σ[:2, :2] * V[:, :2]^T
计算结果为:
1
2
3
4
5B = [
[1.0000000e+00, 2.0000000e+00, 3.0000000e+00],
[4.0000000e+00, 5.0000000e+00, 6.0000000e+00],
[7.0000000e+00, 8.0000000e+00, 9.0000000e+00]
]我们可以看到,B 与 A 完全相同。这是因为 A 本身的秩就是 2,所以我们可以用秩为 2 的矩阵完美地表示它。
如果 A 的秩大于 2,那么 B 就会是一个近似表示,与 A 会有一些误差。但通过保留更多的奇异值和对应的奇异向量,我们可以提高近似的精度。
回到原来的例子:
其中:
现在,我们将低秩矩阵 B 加到原始矩阵 A 上(这就是LoRA产生作用的主要部分),得到一个新的矩阵 C:
1
2
3
4
5
6C = A + B
C = [
[1.04, 2.05, 3.06],
[4.08, 5.10, 6.12],
[7.12, 8.15, 9.18]
]回到LoRA,具体来说,LoRA 的应用方法如下:
- 选择目标层:在 Stable Diffusion 模型中,通常选择 Transformer 块中的注意力层作为 LoRA 的目标层。
- 添加低秩矩阵:在目标层的权重矩阵上添加两个低秩矩阵,分别用于调整查询(query)和值(value)的计算。
- 训练:使用少量目标图像和文本提示,对 LoRA 的参数进行训练。训练过程中,只更新 LoRA 的参数,而保持原始模型的参数不变。
- 推理:在推理时,将 LoRA 的参数与原始模型的参数合并,得到微调后的模型。
CLIP Text Encode:将文本提示词编码成向量表示,为采样过程提供指导。CLIP Text Encoder 的核心是一个 Transformer 模型,它将输入的文本提示词序列转换为一组向量表示。这些向量表示捕捉了文本的语义信息,用于指导图像生成过程。
具体实现过程如下:
分词(Tokenization):将文本提示词分割成一系列 tokens(词或子词)。
举个例子:
假设我们有以下的文本提示词:
1
"一只毛茸茸的橘猫在阳光下懒洋洋地打盹。"
在 Stable Diffusion 中,分词器会将这个提示词分割成一系列 tokens。具体的分词结果取决于所使用的分词器。
1. 基于词的分词器
如果使用基于词的分词器,可能会得到以下结果:
1
["一只", "毛茸茸的", "橘猫", "在", "阳光下", "懒洋洋地", "打盹", "。"]
这种分词方式简单直观,但对于未登录词(Out-of-Vocabulary, OOV)或罕见词的处理能力较弱。
2. 基于子词的分词器
为了更好地处理未登录词和罕见词,Stable Diffusion 通常使用基于子词的分词器,例如 Byte Pair Encoding (BPE) 或 SentencePiece。这些分词器会将词进一步分解为更小的子词单元。
如果使用基于子词的分词器,可能会得到以下结果:
1
["一", "只", "毛", "茸", "茸", "的", "橘", "猫", "在", "阳光", "下", "懒", "洋", "洋", "地", "打", "盹", "。"]
这种分词方式可以更有效地处理未登录词和罕见词,但可能会导致一些词被过度分割。
Stable Diffusion 通常使用基于子词的分词器,如 BPE 或 SentencePiece。
嵌入(Embedding):将每个 token 转换为一个高维向量,表示其语义。
把刚刚分出的每一个token都用一个固定维度的向量进行表示。
假设词嵌入模型将每个 token 嵌入到一个 512 维的向量空间中。那么,嵌入后的结果可能如下所示(这里只是示意性的表示,实际的嵌入向量会更加复杂):
- “一”:[0.123, -0.456, 0.789, …] (512 维向量)
- “只”:[0.321, 0.654, -0.987, …] (512 维向量)
- “毛”:[0.555, -0.234, 0.111, …] (512 维向量)
- …
Stable Diffusion 中的 CLIP Text Encoder 使用预训练的词嵌入模型来实现嵌入。这个词嵌入模型已经在大量的文本数据上进行了训练,学习到了每个词或子词的语义表示。
遇到未登录词(OOV)的处理
当 CLIP Text Encoder 遇到一个之前嵌入字典中没有的词(即未登录词或 OOV)时,通常会采用以下策略之一:
UNK token:
- 大多数词嵌入模型都会预先定义一个特殊的 token,称为 UNK(unknown),用于表示未登录词。
- 当遇到未登录词时,CLIP Text Encoder 会将其替换为 UNK token,然后使用 UNK token 对应的嵌入向量。
- 这种方法简单直接,但可能会导致信息的丢失,因为 UNK token 无法准确表示未登录词的语义。
子词分解:
- 如果使用基于子词的分词器(如 BPE 或 SentencePiece),未登录词可能会被分解成多个子词。
- 如果这些子词都在嵌入字典中,那么 CLIP Text Encoder 可以将它们对应的嵌入向量组合起来,得到未登录词的近似表示。
- 这种方法可以更好地处理未登录词,但仍然可能存在一些误差。
动态嵌入:
- 一些更先进的模型可能会采用动态嵌入技术,根据上下文信息动态生成未登录词的嵌入向量。
- 这种方法可以更准确地表示未登录词的语义,但计算成本较高。
Transformer 编码:将嵌入向量序列输入到 Transformer 模型中,通过多层自注意力机制和前馈神经网络,提取文本的上下文信息和语义关系。
Transformer 编码过程
- 多头自注意力机制
对于每个词的嵌入向量,计算它与其他所有词的嵌入向量的相似度(注意力分数)。
PS: 注意力分数如何计算:
在 Transformer 中,注意力分数是通过计算 query 向量和 key 向量之间的相似度得到的。具体来说,对于每个词的嵌入向量,我们会将其分别线性变换为 query 向量、key 向量和 value 向量。然后,计算 query 向量和所有 key 向量之间的点积,再除以一个缩放因子(通常是 key 向量的维度的平方根),最后通过 softmax 函数将结果归一化为概率分布,得到注意力分数。
接下来一步步说,首先有3个权重矩阵,这三个权重矩阵 (
W_q,W_k,W_v) 是通过模型训练学习得到的。在 Transformer 模型的训练过程中,这些权重矩阵最初是被随机初始化的。然后,通过在大量文本数据上进行训练,模型会根据训练目标(例如,预测下一个词、机器翻译等)不断调整这些权重矩阵的值,使得模型能够更好地捕捉文本中的语义信息和上下文关系。在 Transformer 的自注意力机制中,嵌入向量(embedding vector)会通过这3个权重矩阵,分别生成 query 向量、key 向量和 value 向量。
具体来说:
对于每个输入的嵌入向量
x,我们有三个可学习的权重矩阵:W_q、W_k和W_v。通过矩阵乘法,将嵌入向量
x分别与这三个权重矩阵相乘,得到对应的 query 向量q、key 向量k和 value 向量v:q = x * W_qk = x * W_kv = x * W_v
三个向量的含义
- **Query 向量 (q)**:代表查询,用于和其他元素的 key 向量进行比较,以确定关注的程度。可以理解为“我想要关注什么”。
- **Key 向量 (k)**:代表键,用于被其他元素的 query 向量查询,以确定自己被关注的程度。可以理解为“我有什么信息可以提供”。
- **Value 向量 (v)**:代表值,表示元素的实际信息。在计算注意力权重后,value 向量会被加权平均,得到最终的输出。可以理解为“我实际包含的信息”。
举例说明
假设我们有一个句子 “The cat sat on the mat”,经过嵌入后,得到每个单词的嵌入向量:
- The: [0.1, 0.2, 0.3]
- cat: [0.4, 0.5, 0.6]
- sat: [0.7, 0.8, 0.9]
- on: [0.2, 0.3, 0.1]
- the: [0.3, 0.1, 0.4]
- mat: [0.5, 0.6, 0.2]
现在,我们想要计算单词 “cat” 对其他单词的注意力。首先,我们需要将 “cat” 的嵌入向量通过线性变换转换为 query、key 和 value 向量。假设变换后的结果如下:
- cat:
- query: [0.3, 0.5, 0.2]
- key: [0.6, 0.4, 0.1]
- value: [0.5, 0.7, 0.3]
接下来,我们将 “cat” 的 query 向量与其他所有单词的 key 向量进行比较(通常是计算点积),得到注意力分数。
举个例子中的例子:
假设我们有以下三个词的嵌入向量:
1
2
3词1: [0.1, 0.2, 0.3]
词2: [0.4, 0.5, 0.6]
词3: [0.7, 0.8, 0.9]经过线性变换后,得到它们的 query、key 和 value 向量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14词1:
query: [0.2, 0.3, 0.1]
key: [0.5, 0.1, 0.4]
value: [0.8, 0.6, 0.2]
词2:
query: [0.3, 0.4, 0.2]
key: [0.1, 0.6, 0.3]
value: [0.5, 0.9, 0.1]
词3:
query: [0.1, 0.2, 0.3]
key: [0.4, 0.3, 0.2]
value: [0.7, 0.1, 0.8]现在,我们来计算词1对其他词的注意力分数:
- 词1对词1:
- 点积:[0.2, 0.3, 0.1] · [0.5, 0.1, 0.4] = 0.1 + 0.03 + 0.04 = 0.17
- 缩放因子:√3 ≈ 1.732
- 注意力分数:softmax(0.17 / 1.732)
- 词1对词2:
- 点积:[0.2, 0.3, 0.1] · [0.1, 0.6, 0.3] = 0.02 + 0.18 + 0.03 = 0.23
- 缩放因子:√3 ≈ 1.732
- 注意力分数:softmax(0.23 / 1.732)
- 词1对词3:
- 点积:[0.2, 0.3, 0.1] · [0.4, 0.3, 0.2] = 0.08 + 0.09 + 0.02 = 0.19
- 缩放因子:√3 ≈ 1.732
- 注意力分数:softmax(0.19 / 1.732)
通过 softmax 归一化后,我们会得到词1对三个词的注意力分数,它们相加等于1。
缩放因子的确定
在 Transformer 的注意力机制中,缩放因子通常被设置为
sqrt(d_k),其中d_k是 key 向量的维度。- 这么做的原因:当
d_k较大时,query 和 key 向量之间的点积可能会变得很大。这会导致 softmax 函数的输入值很大,使得 softmax 函数的梯度变得非常小,从而导致训练困难。通过除以sqrt(d_k),可以将点积的值缩放到一个更合理的范围,避免梯度消失问题。
计算注意力分数的原理是:
- 相似度度量:点积可以衡量两个向量之间的相似度。点积越大,两个向量越相似。
- 缩放:除以缩放因子是为了防止点积过大,导致 softmax 函数的梯度消失。
- 归一化:softmax 函数将注意力分数归一化为概率分布,使得我们可以将其解释为词1对其他词的关注程度。
然后回到刚刚Cat的例子,根据注意力分数对所有单词的 value 向量进行加权平均,得到 “cat” 的新的向量表示。这个新的向量表示融合了 “cat” 与其他单词之间的关系信息。
根据注意力分数,对其他词的嵌入向量进行加权平均,得到一个新的向量表示,这个新的向量表示融合了上下文信息。
多头注意力机制会并行地进行多次这样的计算,每个头关注不同的上下文信息。
Softmax 操作
Softmax 操作是一种将向量归一化为概率分布的操作。它将向量中的每个元素转换为一个介于 0 和 1 之间的概率值,并且所有概率值之和等于 1。
具体计算公式如下:
1
softmax(x_i) = exp(x_i) / sum(exp(x_j)) for all j
其中:
x_i是输入向量中的第 i 个元素。exp(x_i)是x_i的指数函数值。sum(exp(x_j))是所有输入元素的指数函数值之和。
举例说明
假设我们有一个向量
x = [1, 2, 3],对其应用 softmax 操作:计算指数函数值:
exp(1) ≈ 2.718exp(2) ≈ 7.389exp(3) ≈ 20.086
计算指数函数值之和:
sum(exp(x_j)) ≈ 2.718 + 7.389 + 20.086 ≈ 30.193
计算 softmax 值:
softmax(1) ≈ 2.718 / 30.193 ≈ 0.090softmax(2) ≈ 7.389 / 30.193 ≈ 0.245softmax(3) ≈ 20.086 / 30.193 ≈ 0.665
可以看到,softmax 操作将原始向量
[1, 2, 3]转换为了一个概率分布[0.090, 0.245, 0.665],所有概率值之和等于 1。softmax 的优势:softmax 函数的一个关键特性是,它能将任意实数向量转换为一个概率分布。这意味着输出的每个元素都在 0 到 1 之间,并且所有元素之和等于 1。这种概率分布的特性使得我们可以将注意力分数解释为模型对不同元素的关注程度。softmax 函数是一个非线性函数,它引入了非线性变换,使得模型能够学习更复杂的模式。在注意力机制中,这种非线性变换可以帮助模型更好地捕捉元素之间的关系,从而实现更准确的注意力分配。softmax 函数的梯度计算相对简单,并且在反向传播过程中梯度不会消失。
得到注意力分数后:
使用这些分数对其他词的 value 向量进行加权平均。具体来说:
- 对于每个词,我们都有一个注意力分数向量,表示它对其他词的关注程度。
- 将注意力分数向量与对应的 value 向量矩阵相乘,得到一个加权后的 value 向量矩阵。
- 对加权后的 value 向量矩阵按行求和,得到每个词的新的向量表示。
举例说明
继续使用之前的例子,假设我们已经计算出了 “cat” 对其他单词的注意力分数:
- The: 0.2
- cat: 0.5
- sat: 0.1
- on: 0.1
- the: 0.05
- mat: 0.05
同时,我们有所有单词的 value 向量矩阵:
1
2
3
4
5
6
7
8[
[0.8, 0.6, 0.2], # The
[0.5, 0.7, 0.3], # cat
[0.1, 0.9, 0.4], # sat
[0.7, 0.2, 0.5], # on
[0.3, 0.4, 0.1], # the
[0.2, 0.1, 0.8] # mat
]现在,我们可以计算 “cat” 的新的向量表示:
1
2
3
4
5
6
7
8cat_new = 0.2 * [0.8, 0.6, 0.2] +
0.5 * [0.5, 0.7, 0.3] +
0.1 * [0.1, 0.9, 0.4] +
0.1 * [0.7, 0.2, 0.5] +
0.05 * [0.3, 0.4, 0.1] +
0.05 * [0.2, 0.1, 0.8]
cat_new = [0.535, 0.595, 0.355]得到的向量表示词在句子中的重要性和与其他词的关系,注意力分数越高,其他词对该词的影响就越大。
- 前馈神经网络
- 前馈神经网络(Feed-Forward Network,FFN)是由多个全连接层组成的网络,它对每个位置的特征进行独立的非线性变换。
- 重复
- Transformer 编码器通常由多层堆叠而成,每一层都会重复上述的多头自注意力和前馈神经网络操作,从而逐步提取更深层次的上下文信息和语义关系。
经过 Transformer 编码后,我们会得到一个新的向量序列。每个向量都融合了其上下文的信息,从而更好地表示了词在句子中的含义。比如原始嵌入向量中,“猫”的向量表示可能只是表示了“猫”这个概念。经过 Transformer 编码后,“猫”的向量表示可能会融合上下文信息,例如“橘猫”、“懒洋洋地打盹”等,从而更准确地表示这只猫的特点。
池化(Pooling):对 Transformer 输出的特征进行池化操作,得到一个固定长度的向量表示,作为整个文本提示的语义嵌入。
假设经过 Transformer 编码后,我们得到了每个单词的新的向量表示(简化了):
- The: [0.2, 0.3, 0.1]
- cat: [0.5, 0.6, 0.2]
- sat: [0.8, 0.1, 0.7]
- on: [0.3, 0.2, 0.4]
- the: [0.1, 0.4, 0.3]
- mat: [0.6, 0.3, 0.5]
现在,我们需要将这些词的向量表示聚合为一个向量,表示整个句子的语义。池化操作就是实现这一目标的方法。
一种常见的池化操作是平均池化(Average Pooling),即对所有词的向量表示取平均值:
1
2
3
4
5
6
7
8句子向量 = ( [0.2, 0.3, 0.1] +
[0.5, 0.6, 0.2] +
[0.8, 0.1, 0.7] +
[0.3, 0.2, 0.4] +
[0.1, 0.4, 0.3] +
[0.6, 0.3, 0.5] ) / 6
句子向量 = [0.416, 0.316, 0.366]池化的作用
- 降维:对于较长的文本,序列可能会很长,不利于后续计算。池化操作可以将不定长序列转换为一个固定长度的向量,从而降低维度提高计算效率。Also, Stable Diffusion 的图像生成器通常需要一个固定长度的向量作为输入
- 获取全局表示:Transformer 编码器输出的每个向量都包含了该词的上下文信息,但它们仍然是局部的表示。池化操作可以将这些局部表示聚合为一个全局表示。
VAE Encoder:将图像编码到潜在空间,降低维度,提高计算效率。其核心是通过神经网络学习一个复杂的非线性函数,将输入图像映射到潜在空间中的一个概率分布, 无法直接从向量中看出它代表什么图片。需要通过 VAE Decoder 将潜在向量解码回图像,才能看到它代表的视觉内容。
潜在空间与模型本身密切相关。
潜在空间的来源
- VAE:在 Stable Diffusion 的训练过程中,VAE 被训练来学习如何将图像编码到潜在空间,并从潜在空间解码回图像。这个学习过程使得 VAE 能够捕捉到图像中的重要特征,并将这些特征表示为低维向量。
- Checkpoint:每个 Stable Diffusion 的 Checkpoint 都包含了一个训练好的 VAE。因此,不同的 Checkpoint 具有不同的 VAE,也就对应着不同的潜在空间。
不同 Checkpoint 之间的潜在空间不通用:在一个 Checkpoint 的潜在空间中表示的图像,可能无法在另一个 Checkpoint 的潜在空间中被准确解码。这是因为不同的 Checkpoint 在训练时使用了不同的数据集和超参数,导致它们学习到的图像特征表示方式有所差异。
PS: 关于图片的维度,例如一张高分辨率,512x512 像素的彩色图片,它有 512x512x3 = 786,432 个维度。这里的维度具体指的是图片中包含的数值元素的数量。在这里,一个维度代表一个像素点上的一个颜色通道的数值。例如,图片左上角第一个像素点的红色通道的值可能为 0.8,绿色通道的值可能为 0.3,蓝色通道的值可能为 0.6。这些数值共同决定了这个像素点的颜色。
与 Transformer 中词向量表示的异同
特点 潜在空间中的图像表示 Transformer 中的词向量表示 表示对象 图像 词或子词 维度 通常较低(例如 64) 通常较高(例如 512 或 768) 获取方式 通过 VAE Encoder 编码得到 通过预训练的词嵌入模型或 Transformer 训练得到 解释性 较弱,需要解码后才能理解其含义 较强,可以直接通过向量之间的距离或相似度来理解语义关系 概率分布 是 否 Sampler:在潜在空间中进行迭代采样,生成图像。VAE Decoder:将潜在空间中的图像解码回像素空间。- VAE Decoder 是变分自编码器(Variational Autoencoder)的解码器部分。VAE Decoder 通常使用转置卷积(transposed convolution)或上采样+卷积的方式来实现上采样操作。转置卷积可以看作是卷积的逆操作,它可以将特征图的空间分辨率扩大。
PS: 卷积,卷积层和CNN:
以图像模糊为例理解卷积
假设我们有一张 5x5 的灰度图像(每个像素的值代表其亮度,范围为 0-255):
1
2
3
4
5
6图像:
100 120 130 140 150
110 130 140 150 160
120 140 150 160 170
130 150 160 170 180
140 160 170 180 190我们想要对这张图像进行模糊处理。一种简单的方法是使用一个 3x3 的平均滤波器(卷积核):
1
2
3
4滤波器:
1/9 1/9 1/9
1/9 1/9 1/9
1/9 1/9 1/9这个滤波器会对图像的每个 3x3 区域进行平均操作,从而实现模糊效果。
卷积操作步骤
将滤波器放置在图像的左上角,使滤波器中心与图像的第一个像素对齐。
计算卷积结果:将滤波器与图像对应区域的元素相乘,然后求和。
对应区域:
1
2
3100 120 130
110 130 140
120 140 150元素乘积:
1
2
3100 * 1/9 120 * 1/9 130 * 1/9
110 * 1/9 130 * 1/9 140 * 1/9
120 * 1/9 140 * 1/9 150 * 1/9求和:
1
2(100 + 120 + 130 + 110 + 130 + 140 + 120 + 140 + 150) / 9
= 126.66 ≈ 127将计算结果 127 填入输出特征图的第一个位置。
滑动滤波器:将滤波器向右滑动一个步长(通常为 1),重复步骤 2,直到滤波器覆盖完图像的第一行。
换行:将滤波器移动到下一行的开头,重复步骤 2 和 3,直到滤波器覆盖完整个图像。
输出
最终,我们会得到一个 3x3 的输出特征图,它代表了模糊后的图像。
当这个滤波器在图像上滑动时,它会对每个 3x3 区域内的像素值进行平均。
这个平均操作的效果是:
降低局部对比度:如果一个像素的值比周围像素的值大很多(例如一个亮点),平均操作会降低它的值,使其更接近周围像素的值。如果一个像素的值比周围像素的值小很多(例如一个暗点),平均操作会增加它的值,使其更接近周围像素的值。
平滑边缘:在图像的边缘处,像素值通常会有较大的变化。平均操作会将边缘像素的值与周围像素的值进行平均,从而使边缘变得不那么尖锐,看起来更模糊。
1
2
3
4输出特征图:
127 133 140
133 140 146
140 146 153PS:更多应用例如:
边缘检测:
垂直边缘检测滤波器在遇到垂直边缘时卷积结果会很大,而在平坦区域时卷积结果会很小。
图像示例
假设我们有下面这张简单的 5x5 灰度图像(为了便于理解,我们使用数字代表像素值,数值越大表示越亮):
1
2
3
4
510 10 10 50 50
10 10 10 50 50
10 10 10 50 50
10 10 10 50 50
10 10 10 50 50可以看到,这张图像中间有一条明显的垂直边缘,左边较暗(像素值为 10),右边较亮(像素值为 50)。
垂直边缘检测滤波器
我们使用如下的 3x3 垂直边缘检测滤波器:
1
2
3-1 0 1
-1 0 1
-1 0 1卷积操作
现在,让我们将滤波器在图像上滑动,看看在不同位置的卷积结果。
- 平坦区域
当滤波器覆盖在图像的平坦区域时,例如左上角的 3x3 区域:
1
2
310 10 10
10 10 10
10 10 10卷积计算结果为:
1
2
3
410 * -1 + 10 * 0 + 10 * 1
+ 10 * -1 + 10 * 0 + 10 * 1
+ 10 * -1 + 10 * 0 + 10 * 1
= 0可以看到,卷积结果为 0。这是因为平坦区域的像素值变化很小,滤波器左右两列的乘积结果相互抵消了。
- 垂直边缘
当滤波器覆盖到图像中间的垂直边缘时,例如中间列的 3x3 区域:
1
2
310 10 50
10 10 50
10 10 50卷积计算结果为:
1
2
3
410 * -1 + 10 * 0 + 50 * 1
+ 10 * -1 + 10 * 0 + 50 * 1
+ 10 * -1 + 10 * 0 + 50 * 1
= 120卷积操作在图像处理中具有以下几个重要作用:
特征提取:卷积层通过滤波器学习提取图像中的各种特征,如边缘、纹理、形状等。这些特征对于图像分类、目标检测、图像分割等任务非常重要。
局部连接:卷积操作只考虑滤波器大小的局部区域,而不是整个图像。这种局部连接性减少了参数数量,提高了计算效率。
权值共享:同一个滤波器在图像的不同位置上共享权重,这意味着模型学习到的特征可以在图像的不同位置上重复使用,进一步减少了参数数量。
PS: 权值共享的含义
在卷积神经网络中,每个卷积层都包含多个滤波器(也称为卷积核)。每个滤波器在图像上滑动时,其权重(即滤波器中的数值)保持不变。这意味着,同一个滤波器在图像的不同位置上执行卷积操作时,使用的都是同一组权重。权值共享减少了参数数量,提高了计算效率。也使得卷积神经网络具有平移不变性,提高了模型的泛化能力。
关于卷积的另一个问题是维度的变化:
但是卷积后的矩阵由9x9变成了3x3, 所以一般为了保证矩阵的维度不发生变化,会使用Padding(填充):
例如,在上面的例子中,如果我们在图像周围添加一层填充(padding=1),那么填充后的图像大小将变为 7x7:
1
2
3
4
5
6
7
8填充后的图像:
0 0 0 0 0 0 0
0 100 120 130 140 150 0
0 110 130 140 150 160 0
0 120 140 150 160 170 0
0 130 150 160 170 180 0
0 140 160 170 180 190 0
0 0 0 0 0 0 0现在,当 3x3 的滤波器在填充后的图像上滑动时,输出的特征图大小仍然是 5x5,与原始图像大小相同。
卷积层
卷积层是卷积神经网络(CNN)中的基本构建块。它由多个滤波器组成,每个滤波器在输入图像或特征图上执行卷积操作,生成一个新的特征图。
- 多个滤波器:卷积层通常有多个滤波器,每个滤波器学习提取图像的不同特征,如边缘、纹理、形状等。
- 特征图:卷积层的输出是一组特征图,每个特征图对应一个滤波器。
- 可学习参数:滤波器的权重是可学习的参数,通过训练数据来调整,使得模型能够提取出对特定任务有用的特征。
Image Output:显示或保存生成的图像。由VAE Decoder解码后生成, 是一个高维矩阵,它精确地描述了一幅图像的像素点和通道信息,再由计算机根据描述显示。
控制因素
这个 workflow 中,主要通过以下因素来控制图像生成:
- 提示词:正向提示词描述你想要生成的图像,负向提示词描述你不想要出现的元素。
- LoRA:LoRA 模型可以影响图像的风格、主题或其他方面。
- 采样器参数:采样器的参数,如采样步数、CFG Scale 等,会影响图像的质量和多样性。
其他 Workflow
虽然你提供的 workflow 是一个基础流程,但 Stable Diffusion 的强大之处在于其灵活性。你可以根据需要添加或修改节点,实现各种各样的效果。例如:
- 图生图:在
VAE Encoder前添加Image Loader节点,加载一张参考图像,实现图生图。 - ControlNet:添加
ControlNet节点,利用额外的控制信息(如边缘、深度图等)来引导图像生成。 - 图像修复:添加
Inpaint节点,利用掩码指定需要修复的区域,实现图像修复。







